vector: 1.046 sec
deque: 1.281 sec
Immer noch klarer Vorteil für vector. Ganz nebenbei sieht man hier auch den Unterschied zwischen int, float und double im Aufwand bezüglich Speichermanagement. Man sollte sich also genau überlegen, ob ein double den höheren Aufwand gegenüber float rechtfertigt, nicht nur bezüglich Speicheranforderung, was heute zumeist kein Problem mehr ist, sondern insbesondere bezüglich Geschwindigkeit.
Setzen Sie die Testklasse bitte wieder auf int num zurück.
Nun machen wir den Härtetest mit N = 100.000.000 (bei 512 MB RAM Arbeitsspeicher eine eindeutige Überlastung, im Normalfall beträgt die Speichernutzung beim konkreten Rechner ca. 350 MB):
N = 100000000
StackV wird gefuellt
time stackV: 59.765 sec
Ctor: 1
Dtor: 372433205
Copycon: 372433205
op=: 0
StackD wird gefuellt
time stackD: 39.61 sec
Ctor: 0
Dtor: 100000000
Copycon: 100000000
op=: 0
Endlich haben wir es geschafft. deque punktet vor vector. Wenn Sie über einen Rechner mit deutlich mehr RAM verfügen, müssen Sie nur die Zahl der Elemente entsprechend anheben. Hier kommt der geringere Speicherbedarf bei Verwendung von deque zum Zug, also noch ein Kriterium, dass man bei der Auswahl beachten sollte. Hier der Screenshot des Windows-Taskmanagers, während zuerst vector und dann deque seine Performance vorführt:
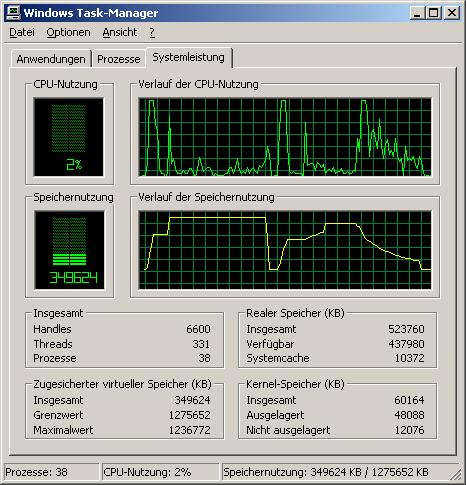
Man erkennt hier auch das einfachere Speichermanagement von vector (array im heap). Bei deque (arrays von arrays im heap) sieht das deutlich komplizierter aus. Deque hat den Vorteil, dass es mit mehreren kleinen Speicherbereichen klar kommt, während vector große Speicherblöcke benötigt.