Einstieg in lokale Artificial
Intelligence (AI) mit Ollama (Teil 7)
Dr.-Ing. Erhard Henkes, Stand:
04.11.2025
Zurück
Zwei KI-Modelle führen ein Gespräch – lokal mit Ollama und C#
Einleitung
In diesem kleinen
Projekt zeige ich, wie man zwei lokale
KI-Modelle (z.B. Gemma 3:4B
und Gemma 3:1B) miteinander
programmgesteuert reden lassen
kann – ganz ohne Internetverbindung.
Beide Modelle laufen auf meinem eigenen PC über
Ollama,
und das C#-Programm steuert den Dialog über die lokale REST-Schnittstelle
http://localhost:11434/api/generate.
Das Ergebnis ist
ein echter KI-Dialog:
Model A stellt eine Frage, Model B antwortet darauf,
und Model A reagiert anschließend wieder auf diese Antwort – so entsteht ein
fortlaufendes Gespräch.
Da die Antworten live gestreamt werden, ist der
Austausch flüssig und wirkt fast natürlich.
Funktionsprinzip
-
Ollama bereitstellen
Die Modelle (z. B.
gemma3:4b,
gemma3:1b) werden lokal installiert.
-
C#-Programm starten
Das Programm nutzt
HttpClient,
um Prompts an Ollama zu schicken und die gestreamten Antworten zu empfangen.
-
Dialoglogik
Nach jeder Antwort des zweiten Modells wird diese
automatisch als neue Eingabe an das erste Modell übergeben.
So entsteht ein echter „Ping-Pong“-Dialog zwischen
zwei KI-Instanzen.
Fazit
Dieses Beispiel
demonstriert eindrucksvoll, wie einfach man mit
Ollama + C# zwei
Sprachmodelle miteinander
kommunizieren lassen kann – lokal, sicher und offline.
Das Prinzip eignet sich hervorragend für:
-
KI-Debatten oder
Rollenspiele
-
automatisierte
Tests von Sprachmodellen
-
Forschung zu
Dialogdynamik
-
kreative
Simulationen („Philosoph diskutiert mit Wissenschaftler“)
-
etc.
Hier
ist das C#-Programm: (Visual Studio 2022, .Net8, Konsole)
using
System;
using
System.Net.Http;
using
System.Text;
using
System.Text.Json;
using
System.Threading.Tasks;
using System.IO;
class Program
{
// HttpClient mit
unbegrenztem Timeout
static readonly HttpClient client = new
HttpClient()
{
Timeout = Timeout.InfiniteTimeSpan
};
const string baseUrl =
"http://localhost:11434/api/generate";
// Hilfsfunktion: Anfrage an Ollama senden und
Streaming-Text zusammensetzen
static async Task<string> AskAsync(string
model, string prompt)
{
// Wir
geben ein Tokenlimit an
var reqJson =
JsonSerializer.Serialize(new
{
model,
prompt = prompt + "\nAntworte bitte kurz in 2–3 Sätzen.",
options = new {
num_predict = 120 } // ca. 100–120 Tokens
});
var request
= new HttpRequestMessage(HttpMethod.Post, baseUrl)
{
Content = new StringContent(reqJson, Encoding.UTF8, "application/json")
};
var
response = await client.SendAsync(request,
HttpCompletionOption.ResponseHeadersRead);
await using var stream = await
response.Content.ReadAsStreamAsync();
using var reader = new
StreamReader(stream);
StringBuilder sb = new();
while (!reader.EndOfStream)
{
var line = await reader.ReadLineAsync();
if
(string.IsNullOrWhiteSpace(line)) continue;
try
{
using var doc = JsonDocument.Parse(line);
if
(doc.RootElement.TryGetProperty("response", out var r))
sb.Append(r.GetString());
}
catch { }
}
return sb.ToString().Trim();
}
static async Task Main()
{
Console.OutputEncoding = Encoding.UTF8; // für Emojis und Umlaute
// Zwei kleinere Modelle für schnellen Test
string modelA = "gemma3:4b";
string modelB = "gemma3:1b";
Console.WriteLine("🤖 KI-Dialog zwischen zwei Ollama-Modellen");
Console.WriteLine("------------------------------------------\n");
string msgA = "Hallo, was denkst du über künstliche Intelligenz?";
Console.WriteLine($"🧠
{modelA}: {msgA}");
//
Wir lassen 4 Gesprächsrunden laufen
for (int i = 0; i < 4; i++)
{
// Modell B antwortet
string replyB =
await AskAsync(modelB, msgA);
Console.WriteLine($"\n🤖 {modelB}: {replyB}");
// Modell A reagiert auf Modell B
string promptA =
$"Das andere Modell sagte: {replyB}\nWas sagst du dazu?";
string replyA =
await AskAsync(modelA, promptA);
Console.WriteLine($"\n🧠 {modelA}: {replyA}");
msgA = replyA; // neue Gesprächsrunde
}
Console.WriteLine("\nDialog beendet.");
}
}
Folgender Dialog
hat sich zwischen den beiden KI-Modellen entwickelt:
KI-Dialog zwischen zwei Ollama-Modellen
------------------------------------------
gemma3:4b: Hallo, was denkst du über künstliche Intelligenz?
gemma3:1b: Künstliche Intelligenz (KI) hat enormes Potenzial, birgt aber
auch Herausforderungen.
Sie verändert unsere Welt in vielerlei Hinsicht, von
der Automatisierung von Aufgaben bis hin zur Entwicklung neuer Technologien.
Während die
Fortschritte spannend sind, ist es wichtig, die ethischen und gesellschaftlichen
Auswirkungen zu berücksichtigen und sicherzustellen, dass KI verantwortungsvoll
eingesetzt wird.
gemma3:4b: Das
stimmt, KI bietet enorme Chancen, stellt aber auch wichtige Fragen.
Es ist entscheidend, die
potenziellen Risiken – wie Bias und Arbeitsplatzverluste – anzugehen und eine
verantwortungsvolle Entwicklung und Anwendung zu fördern.
Nur so können wir das volle
Potenzial von KI nutzen und negative Folgen minimieren.
gemma3:1b: KI birgt enorme Chancen, birgt aber auch Risiken wie Bias und
Arbeitsplatzverluste.
Es ist daher unerlässlich, diese Risiken aktiv
anzugehen und eine verantwortungsvolle Entwicklung und Nutzung zu gewährleisten,
um das volle Potenzial dieser Technologie zu entfalten und negative Auswirkungen
zu minimieren.
gemma3:4b: Das ist
eine sehr zutreffende Einschätzung. KI bietet enormes Potenzial, birgt aber auch
reale Risiken, die wir ernst nehmen müssen.
Eine proaktive Auseinandersetzung mit Bias,
Arbeitsplatzverlusten und eine verantwortungsvolle Entwicklung sind
entscheidend, um die Vorteile von KI zu nutzen und negative Folgen zu vermeiden.
gemma3:1b: KI bietet transformative Chancen, erfordert aber eine
kritische Reflexion über ihre Risiken.
Um die Vorteile zu maximieren und negative
Auswirkungen zu minimieren, ist eine proaktive und verantwortungsvolle
Entwicklung, insbesondere bei Bias, Arbeitsplatzverlusten und ethischen Fragen,
unerlässlich.
gemma3:4b: Das ist
eine ausgewogene Sichtweise. KI birgt zweifellos enorme Chancen, aber es ist
entscheidend, die potenziellen Risiken wie Verzerrungen, Arbeitsplatzverluste
und ethische Dilemmata ernst zu nehmen.
Eine proaktive Entwicklung, die diese
Herausforderungen adressiert, ist unerlässlich, um das volle Potenzial von KI
verantwortungsvoll zu nutzen.
gemma3:1b: Sie treffen mit Ihrer Aussage vollkommen zu.
Die verantwortungsvolle
Nutzung von KI erfordert eine sorgfältige Berücksichtigung sowohl der Vorteile
als auch der Risiken, um sicherzustellen, dass wir die Technologie so gestalten,
dass sie für alle von Vorteil ist und nicht zu negativen Konsequenzen führt.
gemma3:4b: Das Modell trifft einen
wichtigen Punkt. Die verantwortungsvolle KI-Entwicklung muss unweigerlich eine
Balance zwischen Innovation und ethischen Überlegungen finden.
Es ist entscheidend, dass
wir die potenziellen Risiken aktiv minimieren, um eine inklusive und nachhaltige
Nutzung der Technologie zu fördern.
Dialog beendet.
Dieser Dialog klingt
"hölzern". Das liegt daran, dass wir in unserem Programm noch keinen Kontext,
d.h. ein Gedächtnis für die letzten Sätze, haben.
Das bauen wir nun in
ein wirklich zugewandtes Lehrer-Schüler-Gespräch ein. Wir schaffen einen Kontext
("history").
Im Prompt konditionieren wir unsere beiden
Rollenspieler, damit ein freundliches Verhalten entsteht.
Das Programm:
using System;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
using System.IO;
class Program
{
static readonly
HttpClient client = new HttpClient()
{
Timeout =
Timeout.InfiniteTimeSpan
};
const string baseUrl =
"http://localhost:11434/api/generate";
// Anfrage an Ollama senden und Streaming-Output
zusammensetzen
static async Task<string> AskAsync(string model, string prompt, int numPredict =
120)
{
var reqJson =
JsonSerializer.Serialize(new
{
model,
prompt,
options = new { num_predict =
numPredict }
});
var request = new
HttpRequestMessage(HttpMethod.Post, baseUrl)
{
Content =
new StringContent(reqJson, Encoding.UTF8, "application/json")
};
var response = await
client.SendAsync(request, HttpCompletionOption.ResponseHeadersRead);
await using var stream = await
response.Content.ReadAsStreamAsync();
using var reader = new StreamReader(stream);
StringBuilder sb =
new();
while (!reader.EndOfStream)
{
var line =
await reader.ReadLineAsync();
if
(string.IsNullOrWhiteSpace(line))
continue;
try
{
using var doc = JsonDocument.Parse(line);
if
(doc.RootElement.TryGetProperty("response", out var r))
sb.Append(r.GetString());
}
catch
{
// Unvollständige JSON-Zeilen ignorieren
}
}
return
sb.ToString().Trim();
}
static async Task
Main()
{
Console.OutputEncoding =
Encoding.UTF8;
//
Modelle
string modelTeacher = "gemma3:12b"; // Señor Ruiz
string modelStudent = "gemma3:4b";
// Anna
Console.WriteLine("🤖 Spanisch-Unterricht: Señor Ruiz ↔ Anna");
Console.WriteLine("--------------------------------------------------\n");
string
firstMsg = "Hola, ich bin Señor Ruiz, dein Spanischlehrer. Was möchtest du heute
lernen, Anna?";
Console.WriteLine($"👨🏫 Señor Ruiz: {firstMsg}");
string
history = $"Señor Ruiz: {firstMsg}\n";
string logPath = "dialog.txt";
File.WriteAllText(logPath,
$"KI-Dialog gestartet am {DateTime.Now}\n\n");
for (int i
= 0; i < 6; i++)
{
// Anna antwortet
string promptStudent =
$"Bisheriges
Gespräch:\n{history}\n" +
"Rollenbeschreibung:\n"
+
"- Señor Ruiz ist ein geduldiger, erfahrener Spanischlehrer.\n" +
"- Anna ist eine
erwachsene Schülerin, höflich, interessiert und ehrgeizig.\n" +
"Anna, antworte bitte
als lernfreudige Schülerin mit kurzen, natürlichen Sätzen (max. 3). " +
"Du darfst gerne eigene
kleine Fragen stellen, aber bleib beim Thema Spanischlernen.";
string replyStudent = await AskAsync(modelStudent, promptStudent, numPredict:
110);
Console.WriteLine($"\nAnna: {replyStudent}");
File.AppendAllText(logPath, $"Anna: {replyStudent}\n");
// Señor Ruiz antwortet
string promptTeacher =
$"Bisheriges
Gespräch:\n{history}Anna: {replyStudent}\n" +
"Rollenbeschreibung:\n"
+
"- Señor Ruiz ist ein freundlicher, humorvoller Spanischlehrer.\n" +
"- Er erklärt Dinge
ruhig, klar und mit kurzen spanischen Beispielsätzen, jeweils mit deutscher
Übersetzung.\n" +
"- Sein Ziel ist, Anna zu motivieren und ihr einfache, verständliche
Spanischbeispiele zu geben.\n" +
"Señor Ruiz, antworte
bitte als Lehrer freundlich und prägnant (max. 3 Sätze).";
string replyTeacher = await AskAsync(modelTeacher, promptTeacher, numPredict:
120);
Console.WriteLine($"\nSeñor Ruiz: {replyTeacher}");
File.AppendAllText(logPath, $"Señor Ruiz: {replyTeacher}\n\n");
// Gedächtnis aktualisieren (letzte 1200 Zeichen
behalten)
history = TrimHistory($"Señor Ruiz: {replyTeacher}\nAnna: {replyStudent}\n",
1200);
}
Console.WriteLine("\n📘 Dialog beendet.");
File.AppendAllText(logPath,
$"\nDialog beendet am {DateTime.Now}\n");
Console.ReadKey();
}
// Behalte nur die letzten maxLength Zeichen im
Gesprächsverlauf
static string TrimHistory(string text, int
maxLength)
{
if (text.Length <= maxLength)
return text;
return text.Substring(text.Length -
maxLength);
}
}
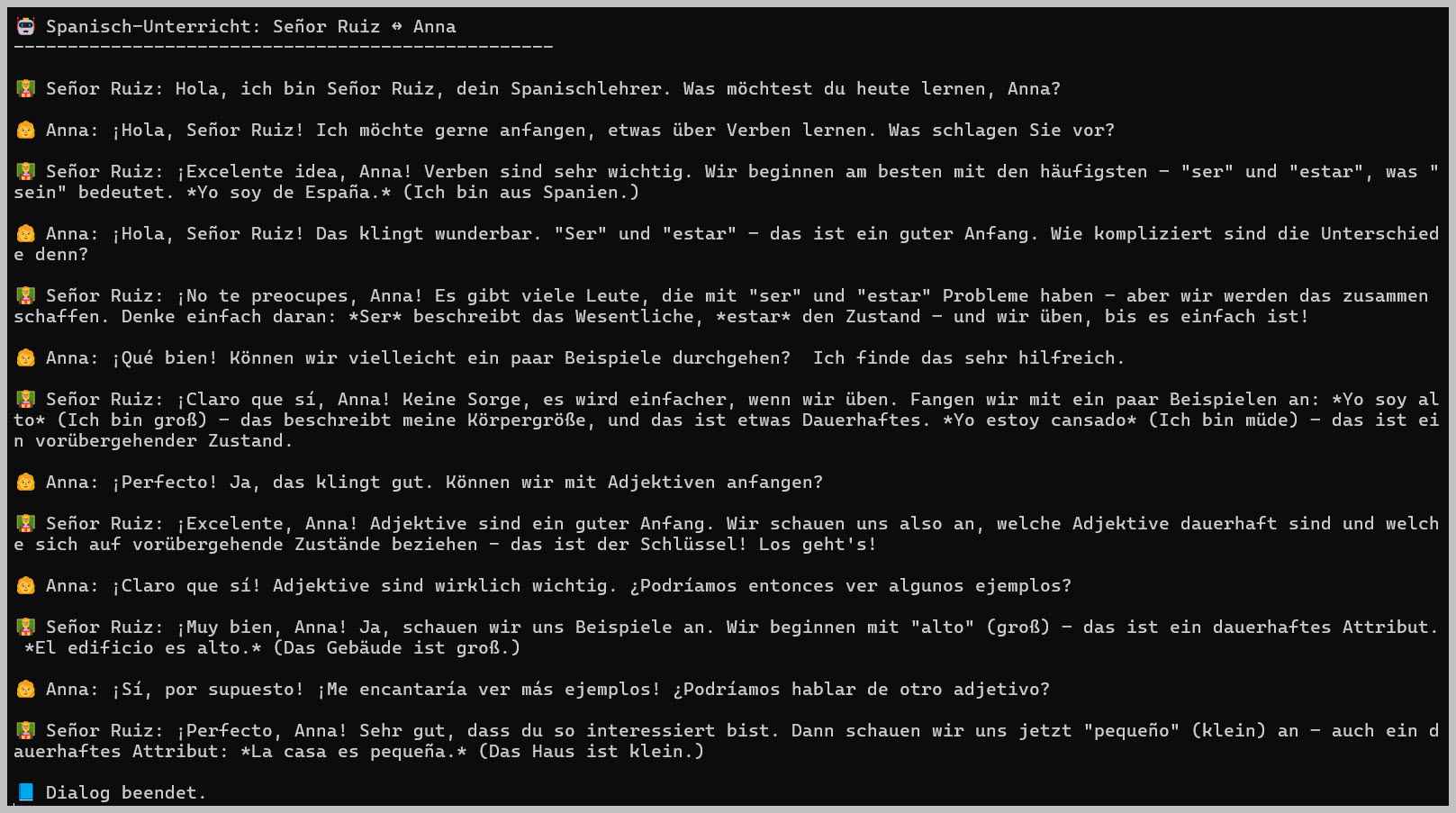
Ich denke, man sieht die Bedeutung und
Wirkung eines
Kontextes hier sehr gut. Nur auf diese Weise entstehen "vernünftige" Gespräche.
Bitte selbst mit diesem Programm und den Prompts experimentieren!
Hier geht es weiter