
| typedef struct oda { // Hardware Data ULONG COM1, COM2, COM3, COM4; // address ULONG LPT1, LPT2, LPT3, LPT4; // address ULONG Memory_Size; // Memory size in Byte // Key Queue UCHAR KEYQUEUE[KQSIZE]; // circular queue buffer UCHAR* pHeadKQ; // pointer to the head of valid data UCHAR* pTailKQ; // pointer to the tail of valid data ULONG KQ_count_read; // number of data read from queue buffer ULONG KQ_count_write; // number of data put into queue buffer }oda_t; // operatings system common data area oda_t ODA; extern oda_t* pODA; extern void initODA(); |
| extern
void keyboard_install(); extern void keyboard_init(); extern UCHAR FetchAndAnalyzeScancode(); extern UCHAR ScanToASCII(); extern void keyboard_handler(struct regs* r); extern int k_checkKQ_and_print_char(); |
| #include
"keyboard.h" #include "os.h" UCHAR ShiftKeyDown = 0; // Variable for Shift Key Down UCHAR KeyPressed = 0; // Variable for Key Pressed UCHAR scan = 0; // Scan code from Keyboard /* Wait until buffer is empty */ void keyboard_init() { while( inportb(0x64)&1 ) inportb(0x60); }; UCHAR FetchAndAnalyzeScancode() { if( inportb(0x64)&1 ) scan = inportb(0x60); // 0x60: get scan code from the keyboard // ACK: toggle bit 7 at port 0x61 UCHAR port_value = inportb(0x61); outportb(0x61,port_value | 0x80); // 0->1 outportb(0x61,port_value &~ 0x80); // 1->0 if( scan & 0x80 ) // Key released? Check bit 7 (10000000b = 0x80) of scan code for this { KeyPressed = 0; scan &= 0x7F; // Key was released, compare only low seven bits: 01111111b = 0x7F if( scan == KRLEFT_SHIFT || scan == KRRIGHT_SHIFT ) // A key was released, shift key up? { ShiftKeyDown = 0; // yes, it is up --> NonShift } } else // Key was pressed { KeyPressed = 1; if( scan == KRLEFT_SHIFT || scan == KRRIGHT_SHIFT ) { ShiftKeyDown = 1; // It is down, use asciiShift characters } } return scan; } UCHAR ScanToASCII() { UCHAR retchar; // The character that returns the scan code to ASCII code scan = FetchAndAnalyzeScancode(); // Grab scancode, and get the position of the shift key if( ShiftKeyDown ) retchar = asciiShift[scan]; // (Upper) Shift Codes else retchar = asciiNonShift[scan]; // (Lower) Non-Shift Codes if( ( !(scan == KRLEFT_SHIFT || scan == KRRIGHT_SHIFT) ) && ( KeyPressed == 1 ) ) //filter Shift Key and Key Release return retchar; // ASCII version else return 0; } void keyboard_handler(struct regs* r) { UCHAR KEY = ScanToASCII(); if(KEY) { *(pODA->pTailKQ) = KEY; ++(pODA->KQ_count_write); if(pODA->pTailKQ > pODA->KEYQUEUE) { --pODA->pTailKQ; } if(pODA->pTailKQ == pODA->KEYQUEUE) { pODA->pTailKQ = (pODA->KEYQUEUE)+KQSIZE-1; } } } int k_checkKQ_and_print_char() { if(pODA->KQ_count_write > pODA->KQ_count_read) { UCHAR KEY = *(pODA->pHeadKQ); ++(pODA->KQ_count_read); if(pODA->pHeadKQ > pODA->KEYQUEUE) { --pODA->pHeadKQ; } if(pODA->pHeadKQ == pODA->KEYQUEUE) { pODA->pHeadKQ = (pODA->KEYQUEUE)+KQSIZE-1; } restore_cursor(); switch(KEY) { case KINS: break; case KDEL: move_cursor_right(); putch('\b'); //BACKSPACE break; case KHOME: move_cursor_home(); break; case KEND: move_cursor_end(); break; case KPGUP: break; case KPGDN: break; case KLEFT: move_cursor_left(); break; case KUP: break; case KDOWN: break; case KRIGHT: move_cursor_right(); break; default: printformat("%c",KEY); // the ASCII character break; } save_cursor(); return 1; } return 0; } void keyboard_install() { /* Installs 'keyboard_handler' to IRQ1 */ irq_install_handler(1, keyboard_handler); keyboard_init(); } |
| #include "os.h" oda_t* pODA = &ODA; void ODA_install() { int i; for(i=0;i<KQSIZE;++i) pODA->KEYQUEUE[i]=0; // circular queue buffer pODA->pHeadKQ = pODA->KEYQUEUE; // pointer to the head of valid data pODA->pTailKQ = pODA->KEYQUEUE; // pointer to the tail of valid data pODA->KQ_count_read = 0; // number of data read from queue buffer pODA->KQ_count_write = 0; // number of data put into queue buffer } |
| #include
"os.h" int main() { k_clear_screen(); gdt_install(); idt_install(); isrs_install(); irq_install(); ODA_install; timer_install(); keyboard_install(); sti(); set_cursor(0,0); printformat(" ************************************************\n"); printformat(" * Welcome to PrettyOS *\n"); printformat(" * Demo of the Key Queue *\n"); printformat(" ************************************************\n"); // demo of the Key Queue (KQ) settextcolor(2,0); UCHAR c=0; while(TRUE) { if( k_checkKQ_and_print_char() ) { ++c; if(c>5) { c=0; settextcolor(4,0); printformat("\nT: %x H: %x WRITE: %i Read: %i ", pODA->pTailKQ, pODA->pHeadKQ, pODA->KQ_count_write, pODA->KQ_count_read); printformat("*T: %c %i *H: %c %i\n", *(pODA->pTailKQ),*(pODA->pTailKQ),*(pODA->pHeadKQ),*(pODA->pHeadKQ)); settextcolor(2,0); } } } return 0; }; |

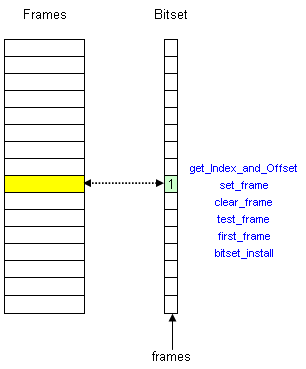
| // A bitset of frames - used or free ULONG NFRAMES = (PHYSICAL_MEMORY/PAGESIZE); ULONG* frames; // pointer to the bitset (functions: set/clear/test) ULONG ind, offs; static void get_Index_and_Offset(ULONG frame_addr) { ULONG frame = frame_addr/PAGESIZE; ind = frame/32; offs = frame%32; } static void set_frame(ULONG frame_addr) { get_Index_and_Offset(frame_addr); frames[ind] |= (1<<offs); } static void clear_frame(ULONG frame_addr) { get_Index_and_Offset(frame_addr); frames[ind] &= ~(1<<offs); } static ULONG test_frame(ULONG frame_addr) { get_Index_and_Offset(frame_addr); return( frames[ind] & (1<<offs) ); } static ULONG first_frame() // find the first free frame in frames bitset { ULONG index, offset; for(index=0; index<(NFRAMES/32); ++index) { if(frames[index] != ULONG_MAX) { for(offset=0; offset<32; ++offset) { if( !(frames[index] & 1<<offset) ) // bit set to zero? return (index*32 + offset); } } } return ULONG_MAX; // no free page frames } static void bitset_install() { frames = (ULONG*) k_malloc( NFRAMES/32, 0, 0 ); k_memset( frames, 0, NFRAMES/32 ); } |
| #define
PAGESIZE 0x00001000
// 0x1000 = 4096 = 4K ULONG placement_address = 0x00200000; ULONG k_malloc(ULONG size, UCHAR align, ULONG* phys) { // later on, there will be the heap code if( align == 1 ) { if( !(placement_address == (placement_address & 0xFFFFF000) ) ) { placement_address &= 0xFFFFF000; placement_address += PAGESIZE; } } if( phys ) { *phys = placement_address; } ULONG temp = placement_address; placement_address += size; // new placement_address is increased return temp; // old placement_address is returned } |
| ULONG physical_address; ULONG virtual_address = memory_alloc( size, align, &physical_address ); printformat ( "phys: %x, virt: %x\n" , physical_address, virtual_address ); |
| asm volatile("mov
%0, %%cr3":: "r"(&kernel_directory->tablesPhysical)); ULONG cr0; asm volatile("mov %%cr0, %0": "=r"(cr0)); cr0 |= 0x80000000; // Enable paging asm volatile("mov %0, %%cr0":: "r"(cr0)); |
| Page Directory (PD) |
10 Bit | zeigt auf 1024 ( = 210 ) Page Tables |
| Page Table (PT) |
10 Bit | zeigt auf 1024 ( = 210 ) Pages |
| Page | 12 Bit Offset | zeigt auf eine spezifische Adresse innerhalb der 4 KByte (212 Byte) umfassenden Page |
| //
cr3: PDBR (Page Directory Base Register) asm volatile( "mov %0, %%cr3" : : "r"(kernel_directory->physicalAddr) ); |
| //
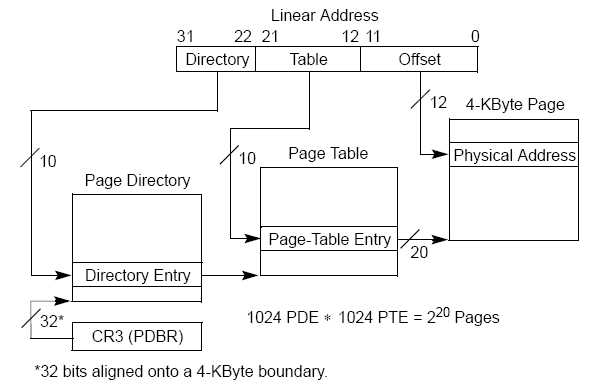
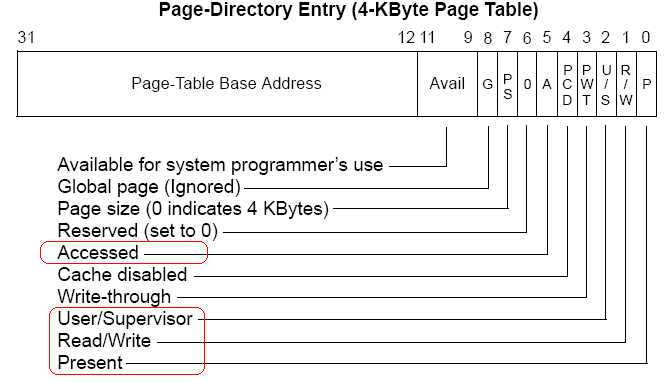
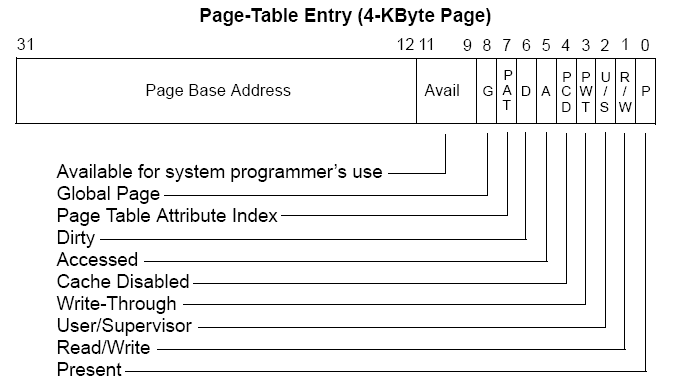
page_directory ==> page_table ==> page typedef struct page { ULONG present : 1; // 0: swapped out, 1: page present in memory ULONG rw : 1; // 0: read-only, 1: read/write ULONG user : 1; // 0: supervisor level, 1: user level ULONG accessed : 1; // Has the page been accessed since last refresh? ULONG dirty : 1; // Has the page been written to since last refresh? ULONG unused : 7; // Combination of unused and reserved bits ULONG frame : 20; // Frame address (shifted right 12 bits) } page_t; typedef struct page_table { page_t pages[1024]; } page_table_t; typedef struct page_directory { ULONG tablesPhysical[1024]; //PDE page_table_t* tables[1024]; ULONG physicalAddr; } page_directory_t; |
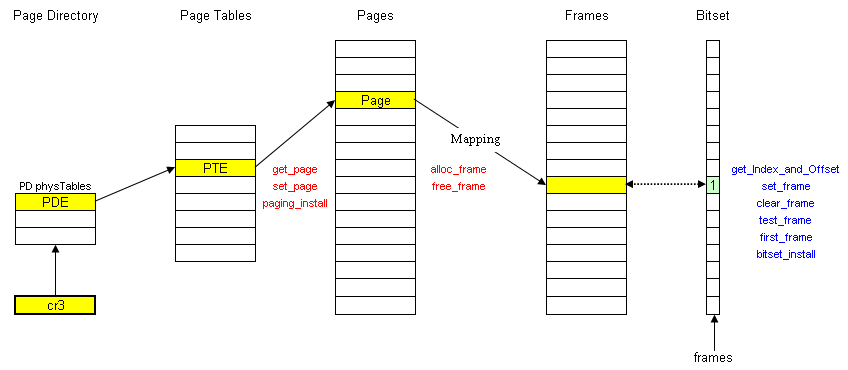
| void
paging_install() { bitset_install(); printformat("make a page directory:\n"); ULONG phys; kernel_directory = (page_directory_t*) k_malloc( sizeof(page_directory_t), 1, &phys ); k_memset(kernel_directory, 0, sizeof(page_directory_t)); kernel_directory->physicalAddr = phys; printformat("map phys addr to virt addr from 0x0 to the end of used memory:\n"); ULONG counter=0, i=0; while( i < (placement_address) ) { page_t* page = set_page(i, kernel_directory); alloc_frame( page, 0, 0 ); i+=PAGESIZE; ++counter; } printformat("\nINFO from paging_install():\n"); printformat("frames: %x\n", frames); printformat("kernel_directory->phys: %x\n", kernel_directory->physicalAddr); printformat("placement_address: %x allocated frames: %x\n\n", placement_address, counter); // cr3: PDBR (Page Directory Base Register) asm volatile( "mov %0, %%cr3" : : "r"(kernel_directory->physicalAddr) ); // read cr0, set paging bit, write cr0 back ULONG cr0; asm volatile("mov %%cr0, %0": "=r"(cr0)); // read cr0 cr0 |= 0x80000000; // set the paging bit in CR0 to enable paging asm volatile("mov %0, %%cr0":: "r"(cr0)); // write cr0 } |
| #include
"os.h" #include "paging.h" int main() { k_clear_screen(); gdt_install(); idt_install(); isrs_install(); irq_install(); ODA_install(); sti(); timer_install(); keyboard_install(); paging_install(); set_cursor(0,0); sleepSeconds(10); analyze_frames_bitset(3); return 0; }; |
| setup
bitset: old: 00200000h sz: 00002000h a: 0 new: 00202000h make a page directory: old: 00202000h sz: 00002004h a: 1 new: 00204004h map phys addr to virt addr from 0x0 to the end of used memory: ?old: 00205000h sz: 00001000h a: 1 new: 00206000h !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! INFO from paging_install(): frames: 00200000h kernel_directory->phys: 00202000h placement_address: 00206000h allocated frames: 00000206h |
Man startet bei
00200000h. bitset_install() liefert frames[...]. Page Directory wird erstellt. Ein Frame wird noch neu allokiert (?), 517 Frames sind bereits allokiert (!). Insgesamt sind 518 (206h) Frames je 4KB (1000h) von 0h bis 206000h allokiert. Die frames-Verwaltung (bitset) beginnt ab 200000h. |
00000000h 11111111111111111111111111111111 00020000h 11111111111111111111111111111111 00040000h 11111111111111111111111111111111 00060000h 11111111111111111111111111111111 00080000h 11111111111111111111111111111111 000A0000h 11111111111111111111111111111111 000C0000h 11111111111111111111111111111111 000E0000h 11111111111111111111111111111111 00100000h 11111111111111111111111111111111 00120000h 11111111111111111111111111111111 00140000h 11111111111111111111111111111111 00160000h 11111111111111111111111111111111 00180000h 11111111111111111111111111111111 001A0000h 11111111111111111111111111111111 001C0000h 11111111111111111111111111111111 001E0000h 11111111111111111111111111111111 00200000h 11111100000000000000000000000000 00220000h 00000000000000000000000000000000 00240000h 00000000000000000000000000000000 00260000h 00000000000000000000000000000000 00280000h 00000000000000000000000000000000 002A0000h 00000000000000000000000000000000 002C0000h 00000000000000000000000000000000 002E0000h 00000000000000000000000000000000 |
Hier erhält man auf einfache Weise eine Übersicht über das Frames-Bitset. |
| void
analyze_PD_PT_Pages(ULONG PDE, ULONG PTE, page_directory_t* dir) { k_clear_screen(); ULONG cr3; asm volatile("mov %%cr3, %0": "=r"(cr3)); // read cr3 printformat( "PDBR cr3: %x\n", cr3 ); printformat( "PD phys. addr.: %x\n", dir->physicalAddr ); int i,j; for(i=0;i<PDE;++i) { printformat( " PDE %d: phys: %x virt: %x\n", i, dir->tablesPhysical[i]&0xFFFFF000, dir->tables[i] ); for(j=0;j<PTE;++j) { printformat( " PTE %d: addr: %x frame-addr: %x\n", j, &(dir->tables[i]->pages[j]), (ULONG)( dir->tables[i]->pages[j].frame_addr)<<12 ); } } } |
| void
fault_handler(struct regs* r) { if (r->int_no < 32) { if (r->int_no == 14) //Page Fault { ULONG faulting_address; asm volatile("mov %%cr2, %0" : "=r" (faulting_address)); // faulting address => CR2 register // The error code gives us details of what happened. int present = !(r->err_code & 0x1); // Page not present int rw = r->err_code & 0x2; // Write operation? int us = r->err_code & 0x4; // Processor was in user-mode? int reserved = r->err_code & 0x8; // Overwritten CPU-reserved bits of page entry? int id = r->err_code & 0x10; // Caused by an instruction fetch? // Output an error message. printformat("Page Fault ("); if (present) printformat("page not present"); if (rw) printformat(" read-only - write operation"); if (us) printformat(" user-mode"); if (reserved) printformat(" overwritten CPU-reserved bits of page entry"); if (id) printformat(" caused by an instruction fetch"); printformat(") at %x - EIP: %x\n", faulting_address, r->eip); } printformat("%s >>> Exception. System Halted! <<<", exception_messages[r->int_no]); for (;;); } } |
| ULONG*
pointer = 0xA0000000; ULONG make_a_page_fault = *pointer; printformat("make_a_page_fault: %x\n", make_a_page_fault); |
| Page
Fault (page not present) at A0000000h - EIP: 00008576h Page Fault >>> Exception. System Halted! <<< |
| OUTPUT_FORMAT("binary") ENTRY(RealMode) phys = 0x00008000; SECTIONS { .text phys : { *(.text) } .data : { *(.data) } .bss : { *(.bss) } _endkernel = .; } |
| //os.h ULONG get_end_kernel(); //delivers end of kernel //os.c extern ULONG endkernel; ULONG get_end_kernel() { return (ULONG) &endkernel; //DON'T FORGET ADDRESS } //ckernel.c int main() { k_clear_screen(); printformat("end of kernel %x\n", get_end_kernel()); //... } |
end of kernel 0000BC00h |
| #include "os.h" #include "paging.h" #include "kheap.h" #define PAGESIZE 0x1000 extern ULONG placement_address; extern heap_t* kheap; extern page_directory_t* kernel_directory; int main() { //... paging_install(); kheap = create_heap(KHEAP_START, KHEAP_START+KHEAP_INITIAL_SIZE, KHEAP_MAX, 0, 0); |
| setup bitset: old: 00200000h sz: 00002000h a: 0 new: 00202000h make a page directory: old: 00202000h sz: 00002004h a: 1 new: 00204004h map phys addr to virt addr from 0x0 to the end of used memory: old: 00205000h sz: 00001000h a: 1 new: 00206000h INFO from paging_install(): frames: 00200000h kernel_directory->phys: 00202000h placement_address: 00206000h allocated frames: 00000206h old: 00206000h sz: 00000020h a: 1 new: 00206020h k_m of heap_t* heap (size: 32): 00206000h before k_memset in place_ordered_array(...) Page Fault (page not present read-only - write operation) at 01000000h - EIP: 00009590h Page Fault >>> Exception. System Halted! <<< |
| //
Map some pages in the heap area and create kernel heap there for( i=KHEAP_START; i<KHEAP_MAX; i+=PAGESIZE ) alloc_frame( set_page(i, kernel_directory), 0, 0); |
| old: 00206000h sz:
00001000h a: 1 new: 00207000h Page Fault (page not present read-only - write operation) at 00206000h - EIP: 000095D0h Page Fault >>> Exception. System Halted! <<< |
| //
Map some pages for the the kernel heap ULONG i = placement_address, num; while( i < (placement_address+0x10000) ) { page_t* page = set_page(i, kernel_directory); num = alloc_frame( page, 0, 0 ); printformat("alloc_frame: %x\n", num*PAGESIZE); i+=PAGESIZE; } |
setup bitset: old: 00200000h sz: 00002000h a: 0 new: 00202000h make a page directory: old: 00202000h sz: 00002004h a: 1 new: 00204004h map phys addr to virt addr from 0x0 to the end of used memory: old: 00205000h sz: 00001000h a: 1 new: 00206000h ... frames: 200000h kernel_directory->phys: 202000h placement_address: 206000h allocated frames: 206h alloc_frame: 00206000h alloc_frame: 00207000h alloc_frame: 00208000h alloc_frame: 00209000h alloc_frame: 0020A000h alloc_frame: 0020B000h alloc_frame: 0020C000h alloc_frame: 0020D000h alloc_frame: 0020E000h alloc_frame: 0020F000h alloc_frame: 00210000h alloc_frame: 00211000h alloc_frame: 00212000h alloc_frame: 00213000h alloc_frame: 00214000h alloc_frame: 00215000h old: 00206000h sz: 00001000h a: 1 new: 00207000h old: 00207000h sz: 00001000h a: 1 new: 00208000h old: 00208000h sz: 00001000h a: 1 new: 00209000h old: 00209000h sz: 00001000h a: 1 new: 0020A000h old: 0020A000h sz: 00000020h a: 1 new: 0020A020h k_m of heap_t* heap (size: 32): 0020A000h HEAP start: 01081000h end: 01100000h max: 01FFF000h kernel mode: 0 read-only: 0 hole 01081000h hole-size: 0007F000h PDE 0: phys: 00205000h virt: 00205000h PTE 0: addr: 00205000h frame-addr: 00000000h PTE 1: addr: 00205004h frame-addr: 00001000h PTE 2: addr: 00205008h frame-addr: 00002000h ... PDE 4: phys: 00206000h virt: 00206000h PTE 0: addr: 00206000h frame-addr: 00216000h PTE 1: addr: 00206004h frame-addr: 00217000h PTE 2: addr: 00206008h frame-addr: 00218000h PDE 5: phys: 00207000h virt: 00207000h PTE 0: addr: 00207000h frame-addr: 00616000h PTE 1: addr: 00207004h frame-addr: 00617000h PTE 2: addr: 00207008h frame-addr: 00618000h
|
| //ckernel.c ULONG addr, phys; addr = k_malloc(0x10000, 1, &phys); printformat("addr: %x phys: %x\n", addr, phys); |
| //kmalloc.c ULONG k_malloc(ULONG size, UCHAR align, ULONG* phys) { if( kheap!=0 ) { void* addr = alloc(size, align, kheap); if (phys != 0) { page_t* page = get_page((ULONG)addr, kernel_directory); *phys = page->frame_addr*PAGESIZE + ((ULONG)addr&0x00000FFF); } printformat("k_m_heap: %x\n", (ULONG)addr); return (ULONG)addr; } //... } |
k_m_heap: 01082000h addr: 01082000h phys: 00298000h |
| kheap
= create_heap(KHEAP_START, KHEAP_START+KHEAP_INITIAL_SIZE, KHEAP_MAX,
0, 0); ULONG addr1, phys1, addr2, phys2, addr3, phys3; addr1 = k_malloc(0x10000, 1, &phys1); printformat("addr1: %x phys1: %x\n", addr1, phys1); addr2 = k_malloc(0x5000, 1, &phys2); printformat("addr2: %x phys2: %x\n", addr2, phys2); kfree(addr1); kfree(addr2); addr3 = k_malloc(0x12000, 1, &phys3); printformat("addr3: %x phys3: %x\n", addr3, phys3); |
addr1: 01082000h phys1: 00298000h addr2: 01093000h phys2: 002A9000h addr3: 01082000h phys3: 00298000h |
| heap_t* heap_install() { // Map some pages for the the kernel heap ULONG i = placement_address, num; while( i < (placement_address+0x10000) ) { page_t* page = set_page(i, kernel_directory); num = alloc_frame( page, 0, 0 ); printformat("alloc_frame: %x\n", num*PAGESIZE); i+=PAGESIZE; } // Map some pages in the heap area and create kernel heap there for( i=KHEAP_START; i<KHEAP_MAX; i+=PAGESIZE ) alloc_frame( set_page(i, kernel_directory), 0, 0); kheap = create_heap(KHEAP_START, KHEAP_START+KHEAP_INITIAL_SIZE, KHEAP_MAX, 0, 0); return kheap; } |
| #include
"os.h" #include "paging.h" #include "kheap.h" //TEST extern heap_t* kheap; //TEST int main() { k_clear_screen(); gdt_install(); idt_install(); isrs_install(); irq_install(); ODA_install(); sti(); timer_install(); keyboard_install(); paging_install(); kheap = heap_install(); //TEST printformat("kernel ends at: %x\n", get_end_kernel()); printformat("&kheap: %x kheap->start %x kheap->end %x\n", &kheap, kheap->start_address, kheap->end_address); k_malloc(0x100000,1,0); printformat("&kheap: %x kheap->start %x kheap->end %x\n", &kheap, kheap->start_address, kheap->end_address); kfree((ULONG*)addr); printformat("&kheap: %x kheap->start %x kheap->end %x\n", &kheap, kheap->start_address, kheap->end_address); //TEST return 0; }; |
kernel ends at: 0000BBB0h &kheap: 0000B2C0h kheap->start 01081000h kheap->end 01100000h expand, new size: 0017F014h k_m_heap: 01082000h &kheap: 0000B2C0h kheap->start 01081000h kheap->end 01201000h contract, new size: 00000000h &kheap: 0000B300h kheap->start 01081000h kheap->end 010F1000h |
Zunächst ein Screen Output des aktuellen Programms:
Der Mechanismus im Betriebssystem verläuft in folgender Reihenfolge:
Beim Auslösen eines Interrupts (verwendet wird vor allem der Timer-Interrupt IRQ0) werden in irq_common_stub zunächst die
Allgemein- und Segment-Register mit Ausnahme von esp mittels push auf den Stack gesichert, um diese mit pop wieder zurück zu holen.
Der Stackpointer esp wird zuletzt auf den Stack gelegt, damit dieser von der Funktion irq_handler1(esp) als Argument übernommen wird.
Der Taskswitch - also ein Wechsel des Prozesses - erfolgt in der Funktion task_switch1(esp), die den Stackpointer widerum als Argument übernimmt,
um ihn in der Struktur task zu speichern.
| isr.asm irq_common_stub: push eax push ecx push edx push ebx push ebp push esi push edi push ds push es push fs push gs mov ax, 0x10 mov ds, ax mov es, ax mov fs, ax mov gs, ax push esp ; parameter of _irq_handler1 call _irq_handler1 irq.c ULONG irq_handler1(ULONG esp) { ULONG retVal; struct regs* r = (struct regs*)esp; if(!pODA->ts_flag) retVal = esp; else retVal = task_switch1(esp); //new task's esp //... return retVal; } task.c ULONG task_switch1(ULONG esp) { // ... current_task->esp = esp; // save esp current_task = current_task->next; // task switch if(!current_task) current_task = ready_queue; // the last task? go to the first task current_directory = current_task->page_directory; // setup correct PD asm volatile("mov %0, %%cr3" : : "r" (current_directory->physicalAddr)); // task's address space tss_entry.esp0 = (current_task->kernel_stack)+KERNEL_STACK_SIZE; // address of kernel stack return current_task->esp; // return new task's esp } isr.asm global _irq_tail _irq_tail: mov esp, eax ; return value: changed or unchanged esp pop gs pop fs pop es pop ds pop edi pop esi pop ebp pop ebx pop edx pop ecx pop eax add esp, 8 iret |
| task_t*
create_task(void* entry) { cli(); page_directory_t* directory = clone_directory(current_directory); task_t* new_task = (task_t*)k_malloc(sizeof(task_t),0,0); new_task->id = next_pid++; new_task->page_directory = directory; new_task->kernel_stack = k_malloc(KERNEL_STACK_SIZE,1,0)+KERNEL_STACK_SIZE; new_task->next = 0; task_t* tmp_task = (task_t*)ready_queue; while (tmp_task->next) tmp_task = tmp_task->next; tmp_task->next = new_task; ULONG* kernel_stack = (ULONG*) new_task->kernel_stack; *(--kernel_stack) = 0x0200; // eflags = interrupts aktiviert und iopl = 0 *(--kernel_stack) = 0x08; // cs *(--kernel_stack) = (ULONG)entry; // eip *(--kernel_stack) = 0; // error code *(--kernel_stack) = 0; // interrupt nummer // general purpose registers without esp *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; // data segment registers *(--kernel_stack) = 0x10; *(--kernel_stack) = 0x10; *(--kernel_stack) = 0x10; *(--kernel_stack) = 0x10; new_task->esp = (ULONG)kernel_stack; new_task->eip = (ULONG)irq_tail; sti(); return new_task; } |
|
tasking_install(); task_t* task2 = create_task( baa ); task_t* task3 = create_task( moo ); pODA->ts_flag = 1; while(TRUE) printformat("%d", getpid()); |
| struct tss_entry { USHORT prev_tss; USHORT reserved10; ULONG esp0; USHORT ss0; USHORT reserved09; ULONG esp1; USHORT ss1; USHORT reserved08; ULONG esp2; USHORT ss2; USHORT reserved07; ULONG cr3; ULONG eip; ULONG eflags; ULONG eax; ULONG ecx; ULONG edx; ULONG ebx; ULONG esp; ULONG ebp; ULONG esi; ULONG edi; USHORT es; USHORT reserved06; USHORT cs; USHORT reserved05; USHORT ss; USHORT reserved04; USHORT ds; USHORT reserved03; USHORT fs; USHORT reserved02; USHORT gs; USHORT reserved01; USHORT ldt; USHORT reserved00; USHORT trap; //bit0 only! bit1...15 reserved USHORT iomap_base; } |
| void gdt_install() { gdt_register.limit = (sizeof(struct gdt_entry) * NUMBER_GDT_GATES)-1; gdt_register.base = (ULONG) &gdt; gdt_set_gate(0, 0, 0, 0, 0); // NULL descriptor gdt_set_gate(1, 0, 0xFFFFFFFF, 0x9A, 0xCF); // CODE, privilege level 0 for kernel code gdt_set_gate(2, 0, 0xFFFFFFFF, 0x92, 0xCF); // DATA, privilege level 0 for kernel code write_tss (3, 0x10, 0x0); //num, ss0, esp0 gdt_flush((ULONG)&gdt_register); // inclusive gdt_load() in assembler code tss_flush(); //in flush.asm: privilege level 0 for kernel mode 0x28 } // in descriptor_tables.c void write_tss(int num, USHORT ss0, ULONG esp0) { ULONG base = (ULONG) &tss_entry; ULONG limit = sizeof(tss_entry); gdt_set_gate(num, base, limit, 0xE9, 0x00); //access = 0xE9, granularity = 0x0 k_memset(&tss_entry, 0, sizeof(tss_entry)); tss_entry.ss0 = ss0; // Set the kernel stack segment. tss_entry.esp0 = esp0; // Set the kernel stack pointer. tss_entry.cs = 0x08; tss_entry.ss = tss_entry.ds = tss_entry.es = tss_entry.fs = tss_entry.gs = 0x10; } // in flush.asm GLOBAL _tss_flush _tss_flush: mov ax, 0x18 ; Load the index of our TSS structure ltr ax ; Load ... into the task state register. ret |
| Befehl |
Bedeutung |
| print-stack |
zeigt
die Stack-Inhalte |
| s [count] | man geht [count] Schritte (s = step) im Assemblercode vorwärts |
| c | man setzt das Programm fort bis zum nächsten breakpoint bzw. bis zum Ende (c = continue) |
| lb [addr] | setzt
einen lineraen
Adress-Breakpoint (Info aus kernel.map) |
| r | zeigt die Register |
| info eflags | zeigt die EFLAGS |
| info
cpu |
zeigt
alles Wichtige in der
Gesamtsicht |
| watch
read [addr] |
Eine
physische Adresse wird zur Überwachungsliste hinzu gefügt |
| watch |
Überwachungsliste
anzeigen |
0x000084e0 _baa 0x000084b8 _moo 0x00008406 _irq0 0x000096f0 _irq_handler1 0x00008495 _irq_tail |
| // util.c inline void nop() { asm volatile ( "nop" ); } // Do nothing // ckernel.c void f2() { while(TRUE) { settextcolor(getpid(),0); putch(getpid()+'@'); nop(); nop(); //... } } |
| ; prolog des callee push ebp ; ebp des callers sichern mov ebp, esp ; ebp des callee erstellen nop ; body des callee ; epilog des callee pop ebp ; ebp des callers wiederherstellen ret ; Rücksprung zum gesicherten eip des callers |
| Stackpointer |
Inhalt |
Bedeutung
des Inhalts |
| 0x402057dc [ebp +
0] des callee |
0x402057fc | Stackframe (ebp) des caller |
| 0x402057e0
[ebp + 4] |
0x000082ea | Instruction Pointer (eip) des caller = Rücksprungadresse |
| 0x402057e4 [ebp +
8] |
... | (argument1, in diesem
einfachen Fall nicht vorhanden) |
| 0x402057e8 [ebp +
12] |
... | (argument2, in diesem einfachen Fall nicht vorhanden) |
| int foo2(int a,
int b) { int loc1, loc2, loc3; loc1 = a + b; loc3 = loc2 - loc1; int retVal = loc3 + 42; return retVal; } void f2() { while(TRUE) { settextcolor(getpid(),0); putch(getpid()+'@'); nop(); foo2(42,0); //... } } |
| int foo2(int a,
int b) { int volatile loc1, loc2, loc3; loc1 = a + b; loc3 = loc2 - loc1; int retVal = loc3 + 42; return retVal; } void f2() { //... } |
| Die Register EAX, ECX, und EDX
sind reserviert für die Verwendung
innerhalb der Funktion, werden also unter Umständen verändert. Rückgabewerte werden im EAX-Register zurückgegeben. |
| Scratch registers are registers
that can be used for temporary storage
without restrictions (also called caller-save
or volatile registers): EAX, ECX, EDX. Callee-save registers are registers that you have to save before using them and restore after using them (also called non-volatile registers). You can rely on these registers having the same value after a call as before the call: EBX, ESI, EDI, EBP |
nasmw -f bin file_data.asm -o file_data.dat |
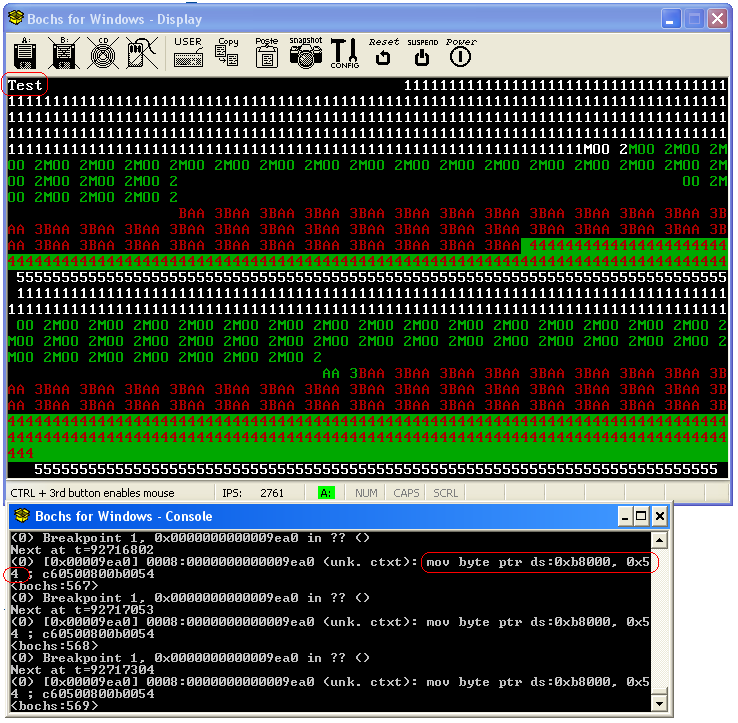
| ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ; Test Program for PrettyOS ; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; [BITS 32] start: Mov [0x000b8000], byte 'T' Mov [0x000b8002], byte 'e' Mov [0x000b8004], byte 's' Mov [0x000b8006], byte 't' Ret |
| process.asm:
global _file_data_start global _file_data_end _file_data_start: incbin "file_data.dat" _file_data_end: |
| void
moo() { while(TRUE) { settextcolor(2,0); printformat("MOO %d", getpid()); // <-- cow settextcolor(15,0); } } void baa() { while(TRUE) { settextcolor(4,0); printformat("BAA %d", getpid()); // <- sheep settextcolor(15,0); } } void surprise(ULONG a, ULONG b) // <- function with 2 arguments { asm volatile ("push %0" :/* no output registers */: "r" (b)); asm volatile ("push %0" :/* no output registers */: "r" (a)); while(TRUE) { asm volatile ("call _settextcolor"); printformat("%d", getpid()); settextcolor(15,0); } } void test() // <- program from outside "loaded" by incbin ... { while(TRUE) { asm volatile ("call _file_data_start"); printformat("%d", getpid()); settextcolor(15,0); } } //main: task_t* task2 = create_task(moo); task_t* task3 = create_task(baa); task_t* task4 = create_task2(surprise,4,2); task_t* task5 = create_task(test); //task.c task_t* create_task2(void* entry, ULONG arg1, ULONG arg2) { //... ULONG* kernel_stack = (ULONG*) new_task->kernel_stack; *(--kernel_stack) = arg2; // arg2 *(--kernel_stack) = arg1; // arg1 *(--kernel_stack) = 0x0; // return address dummy *(--kernel_stack) = 0x0202; // eflags = interrupts aktiviert und iopl = 0 //... return new_task; } |
| typedef struct fs_node { CHAR name[128]; // The filename. ULONG mask; // The permissions mask. ULONG uid; // The owning user. ULONG gid; // The owning group. ULONG flags; // Includes the node type. ULONG inode; // This is device-specific - provides a way for a filesystem to identify files. ULONG length; // Size of the file, in bytes. ULONG impl; // An implementation-defined number. read_type_t read; write_type_t write; open_type_t open; close_type_t close; readdir_type_t readdir; finddir_type_t finddir; struct fs_node* ptr; // Used by mountpoints and symlinks. } fs_node_t; |
| typedef struct { ULONG nfiles; // The number of files in the ramdisk. } initrd_header_t; |
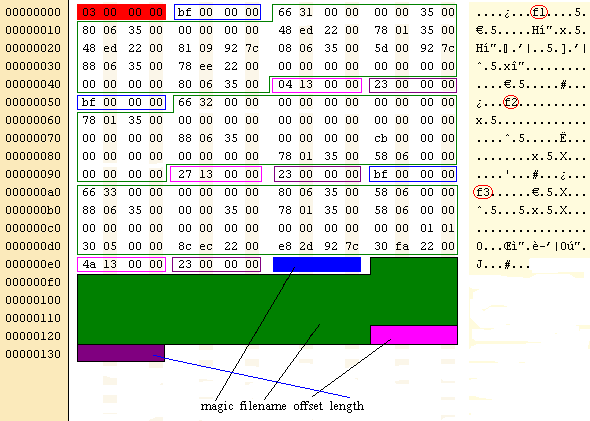
| typedef struct { ULONG magic; // Magic number, for error checking. CHAR name[64]; // Filename. ULONG off; // Offset in the initrd that the file starts. ULONG length; // Length of the file. } initrd_file_header_t; |
| ULONG ramdisk_start =
0x40081000;
// In the heap fs_root = install_initrd( ramdisk_start ); |
| ;
data for ramdisk global _file_data_start global _file_data_end global _prog_start _file_data_start: incbin "file_data.da1" _prog_start: incbin "file_data.dat" _file_data_end: |
| k_memcpy(
(void*)ramdisk_start,&file_data_start,(ULONG)&file_data_end -
(ULONG)&file_data_start
); |
|
Welcome
to
PrettyOS 0.08 HEAP
start:
40081000h end: 40200000h max: 4FFFF000h kernel mode: 0 read-only: 0 first
task
structure: 0020A000h VFS &
RAM Disk install Found file dev
(directory) Found file f1
contents: "PrettyOS:
My filename
is test1.txt!" Found file f2
contents: "PrettyOS:
My filename
is test2.txt!" Found file f3
contents: "PrettyOS:
My filename
is test3.txt!" |
| 03 00 00 00 ¿ f1 (Offset) (Länge) ¿ f2 (Offset) (Länge) ¿ f3 (Offset) (Länge) ...... PrettyOS: My filename is test1.txt!PrettyOS: My filename is test2.txt!PrettyOS: My filename is test3.txt! |

| ULONG
nfiles;
// The number of files in
the ramdisk. -------------------------------------------------------------------------- ULONG magic; // Magic number, for error checking. CHAR name[64]; // Filename. ULONG off; // Offset in the initrd that the file starts. ULONG length; // Length of the file. -------------------------------------------------------------------------- ULONG magic; // Magic number, for error checking. CHAR name[64]; // Filename. ULONG off; // Offset in the initrd that the file starts. ULONG length; // Length of the file. -------------------------------------------------------------------------- // etc. |

| Welcome
to PrettyOS ... ... VFS & RAM Disk install ... Found file dev (directory) Found file f1 contents: "PrettyOS: My filename is test1.txt!" Found file f2 contents: "PrettyOS: My filename is test2.txt!" Found file f3 contents: "PrettyOS: My filename is test3.txt!" Found file Test-Programm contents: "Æ€TÆ€eÆ€sÆ€tÃ" |
|
// list the content of files
ULONG i = 0; struct dirent* node = 0; while( (node = readdir_fs(fs_root, i)) != 0) { printformat("Found file %s\n",node->name); fs_node_t* fsnode = finddir_fs(fs_root, node->name); if((fsnode->flags & 0x7) == FS_DIRECTORY) { printformat("\t(directory)\n"); } else { printformat("\t contents: \""); CHAR buf[256]; ULONG sz = read_fs(fsnode, 0, fsnode->length, buf); ULONG j; for(j=0; j<sz; ++j) printformat("%c",buf[j]); printformat("\"\n"); } ++i; } |
| #include
... ... ULONG ramdisk_start = 0x40081000; // In the heap UCHAR address_TEST[256]; ... void test() { while(TRUE) { asm volatile("call *%0"::"r"(address_TEST)); ... } } int main() { ... k_memcpy((void*)ramdisk_start, &file_data_start, (ULONG)&file_data_end - (ULONG)&file_data_start); // process.asm fs_root = install_initrd(ramdisk_start); // list the content of files <- data from outside "loaded" by incbin ... ULONG i = 0; struct dirent* node = 0; while( (node = readdir_fs(fs_root, i)) != 0) { ... UCHAR buf[256]; ULONG sz = read_fs(fsnode, 0, fsnode->length, buf); ULONG j; for(j=0; j<sz; ++j) { if( k_strcmp(node->name,"Test-Programm")==0 ) { printformat("%x ",buf[j]); address_TEST[j] = buf[j]; } else printformat("%c",buf[j]); } printformat("\"\n"); } ++i; printformat("\naddress_TEST: %x",address_TEST); } ... create_task(test); ... } |
| Found file
Test-Programm contents: "C6h 05h 00h 80h 0Bh 00h 54h C6h 05h 02h 80h 0Bh 00h 65h C6h 05h 04h 80h 0Bh 00h 73h C6h 05h 06h 80h 0Bh 00h 74h C3h " address_TEST: D6B0h |
| // syscall.h #define DECL_SYSCALL0(fn) int syscall_##fn(); #define DECL_SYSCALL1(fn,p1) int syscall_##fn(p1); // etc. #define DEFN_SYSCALL0(fn, num) \ int syscall_##fn() \ { \ int a; \ asm volatile("int $0x7F" : "=a" (a) : "0" (num)); \ return a; \ } #define DEFN_SYSCALL1(fn, num, P1) \ int syscall_##fn(P1 p1) \ { \ int a; \ asm volatile("int $0x7F" : "=a" (a) : "0" (num), "b" ((int)p1)); \ return a; \ } // etc. DECL_SYSCALL1(puts, UCHAR*) DECL_SYSCALL1(putch, UCHAR) DECL_SYSCALL2(settextcolor, UCHAR, UCHAR) DECL_SYSCALL0(getpid) DECL_SYSCALL0(f3) DECL_SYSCALL0(nop) DECL_SYSCALL0(switch_context) // ------------------------------------------------------------------- // syscall.c DEFN_SYSCALL1( puts, 0, UCHAR* ) DEFN_SYSCALL1( putch, 1, UCHAR ) DEFN_SYSCALL2( settextcolor, 2, UCHAR, UCHAR ) DEFN_SYSCALL0( getpid, 3 ) DEFN_SYSCALL0( f3, 4 ) DEFN_SYSCALL0( nop, 5 ) DEFN_SYSCALL0( switch_context, 6 ) #define NUM_SYSCALLS 7 static void* syscalls[NUM_SYSCALLS] = { &puts, &putch, &settextcolor, &getpid, &f3, &nop, &switch_context }; |
| task_t*
create_task(void* entry, UCHAR privilege) { cli(); page_directory_t* directory = clone_directory(current_directory); task_t* new_task = (task_t*)k_malloc(sizeof(task_t),0,0); new_task->id = next_pid++; new_task->page_directory = directory; new_task->kernel_stack = k_malloc(KERNEL_STACK_SIZE,1,0)+KERNEL_STACK_SIZE; new_task->next = 0; task_t* tmp_task = (task_t*)ready_queue; while (tmp_task->next) tmp_task = tmp_task->next; tmp_task->next = new_task; ULONG* kernel_stack = (ULONG*) new_task->kernel_stack; ULONG code_segment=0x08, data_segment=0x10; *(--kernel_stack) = 0x0; // return address dummy if(privilege == 3) { // general information: Intel 3A Chapter 5.12 *(--kernel_stack) = new_task->ss = 0x23; // ss *(--kernel_stack) = new_task->kernel_stack; // esp0 code_segment = 0x1B; // 0x18|0x3=0x1B } *(--kernel_stack) = 0x0202; // eflags = interrupts activated and iopl = 0 *(--kernel_stack) = code_segment; // cs *(--kernel_stack) = (ULONG)entry; // eip *(--kernel_stack) = 0; // error code *(--kernel_stack) = 0; // interrupt nummer // general purpose registers w/o esp *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; *(--kernel_stack) = 0; if(privilege == 3) data_segment = 0x23; // 0x20|0x3=0x23 *(--kernel_stack) = data_segment; *(--kernel_stack) = data_segment; *(--kernel_stack) = data_segment; *(--kernel_stack) = data_segment; //setup TSS tss_entry.ss0 = 0x10; tss_entry.esp0 = new_task->kernel_stack; tss_entry.ss = data_segment; //setup task_t new_task->ebp = 0xd00fc0de; // test value new_task->esp = (ULONG)kernel_stack; new_task->eip = (ULONG)irq_tail; new_task->ss = data_segment; sti(); return new_task; } |
| void gdt_install() { /* Setup the GDT pointer and limit */ gdt_register.limit = (sizeof(struct gdt_entry) * NUMBER_GDT_GATES)-1; gdt_register.base = (ULONG) &gdt; /* GDT GATES - desriptors with pointers to the linear memory address */ gdt_set_gate(0, 0, 0, 0, 0); // NULL descriptor gdt_set_gate(1, 0, 0xFFFFFFFF, 0x9A, 0xCF); // CODE, privilege level 0 for kernel code gdt_set_gate(2, 0, 0xFFFFFFFF, 0x92, 0xCF); // DATA, privilege level 0 for kernel code //... gdt_set_gate(3, 0, 0xFFFFFFFF, 0xFA, 0xCF); // User mode code segment gdt_set_gate(4, 0, 0xFFFFFFFF, 0xF2, 0xCF); // User mode data segment //... write_tss(5, 0x10, 0x0); // num, ss0, esp0 gdt_flush((ULONG)&gdt_register); tss_flush(); } |
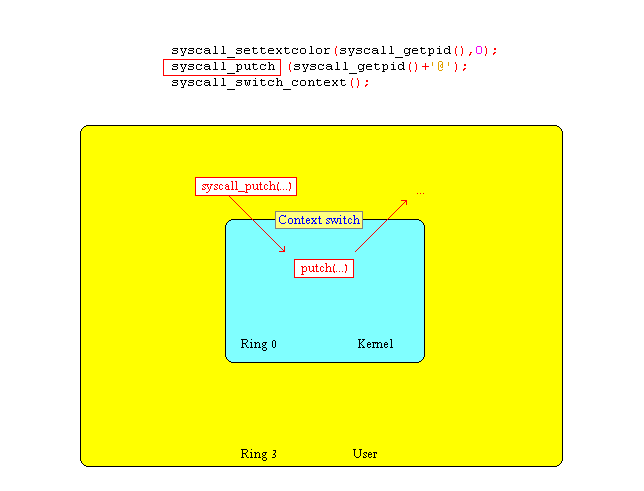
| void f2() { while(TRUE) { settextcolor(getpid(),0); putch(getpid()+'@'); switch_context(); } } void f3() //user mode at ring 3 requires syscall_... { while(TRUE) { syscall_settextcolor(syscall_getpid(),0); syscall_putch(syscall_getpid()+'@'); syscall_switch_context(); } } //... // create two additional tasks /* task_t* task2 = */ create_task (f2,0); // kernel mode (ring 0) /* task_t* task3 = */ create_task (f3,3); // user mode (ring 3) |
| void f3() //user mode at ring 3 requires
syscall_... { while(TRUE) { /*syscall_*/settextcolor(syscall_getpid(),0); syscall_putch(syscall_getpid()+'@'); syscall_switch_context(); } } |
| AB Page Fault ( read-only - write operation user-mode) at 0000D6F4h - EIP: 0000D025h err_code: 00000007h address(eip): 0000D025h edi: 00000000h esi: 00000000h ebp: 402097DCh eax: 00000003h ebx: 00000000h ecx: 00000000h edx: 00000003h cs: 0000001Bh ds: 00000023h es: 00000023h fs: 00000023h gs 00000023h ss 00000023h int_no 14 eflags 00010206h useresp 402097DCh Page Fault >>> Exception. System Halted! <<< |
| global _isr127 ; syscall _isr127: cli push dword 0 push dword 127 jmp isr_common_stub isr_common_stub: push eax push ecx push edx push ebx push ebp push esi push edi push ds push es push fs push gs mov ax, 0x10 mov ds, ax mov es, ax mov fs, ax mov gs, ax push esp ; parameter of _fault_handler call _fault_handler ... |
| ULONG fault_handler(ULONG esp) { ULONG retVal; struct regs* r = (struct regs*)esp; if(!pODA->ts_flag){ retVal = esp; } else { if(r->int_no == 127) { retVal = esp; } else { retVal = task_switch(esp); } } //... if (r->int_no == 127) { syscall_handler(r); } return retVal; } void syscall_handler(struct regs* r) { if( r->eax >= NUM_SYSCALLS ) return; // Syscall number in EAX valid? void* address = syscalls[r->eax]; // Syscall address int ret; asm volatile (" \ push %1; \ push %2; \ push %3; \ push %4; \ push %5; \ call *%6; \ add $20, %%esp; \ " : "=a" (ret) : "r" (r->edi), "r" (r->esi), "r" (r->edx), "r" (r->ecx), "r" (r->ebx), "r" (address)); r->eax = ret; } |
|
global _fault_tail _fault_tail: mov esp, eax ; return value: changed or unchanged esp pop gs pop fs pop es pop ds pop edi pop esi pop ebp pop ebx pop edx pop ecx pop eax add esp, 8 iret |
| Format |
Bemerkungen |
| aout: | packt 16/32 bit code gemischt,
passt für den ld 2.13, aber nicht für den Linker in den cross-tools |
| coff: | funktioniert nur mit reinem 32 bit code, passt für den ld 2.13 und Linker in den cross-tools |
| elf: | Linker in den cross-tools
verarbeitet dieses Format, jedoch nicht der ältere ld 2.13 aus DJGPP |
| SOURCES =
kernel.asm $(filter-out file_data.asm boot.asm kernel.asm
make_initrd.c,$(wildcard *.asm *.c)) OBJECTS = $(addsuffix .o,$(basename $(SOURCES))) ASFLAGSBIN= -O32 -f bin ASFLAGSOBJ= -O32 -f elf NASM = nasmw CFLAGS= -O -ffreestanding -fleading-underscore CC= i586-elf-gcc LDFLAGS= -T kernel.ld -Map kernel.map LD= i586-elf-ld all: boot.bin ckernel.bin make -s image make -s floppyimage process.asm: file_data.dat file_data.da1 file_data.dat: file_data.asm $(NASM) $(ASFLAGSBIN) $< -o $@ boot.bin: boot.asm $(NASM) $(ASFLAGSBIN) $< -o $@ %.o: %.asm $(NASM) $(ASFLAGSOBJ) $< -o $@ ckernel.bin: $(OBJECTS) $(LD) $(LDFLAGS) $+ -o $@ image: cmd /c copy /b boot.bin + ckernel.bin MyOS del *.o del *.bin cmd /c rename MyOS MyOS.bin floppyimage: partcopy MyOS.bin 0 7000 -f0 # $< Erste Abhängigkeit # $+ Liste aller Abhängigkeiten # $@ Name des Targets |

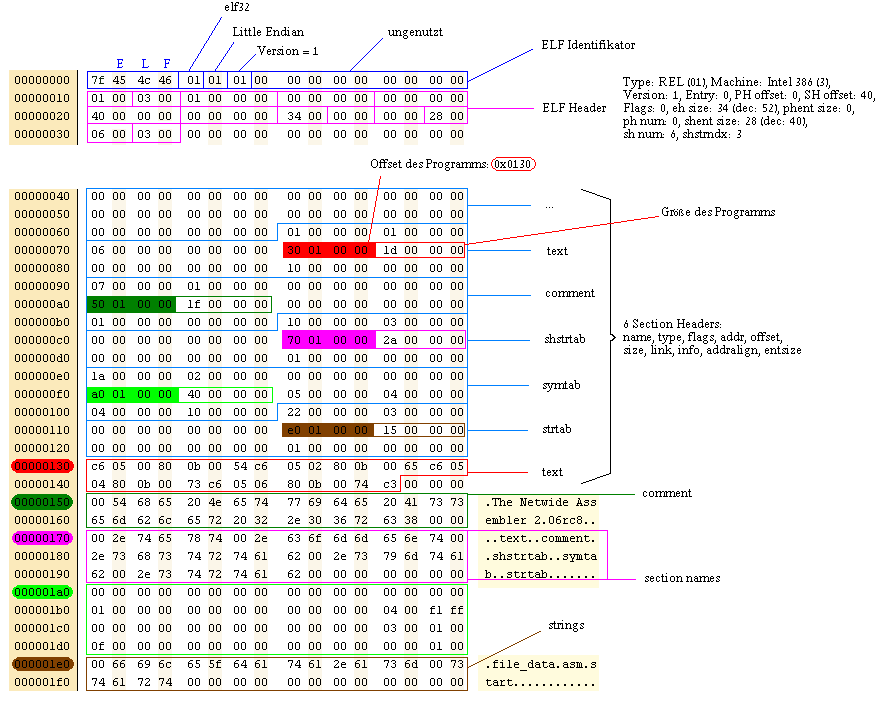
| G:\OSDev\Test\50
cp>i586-elf-readelf.exe -a file_data.dat ELF Header: Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 Class: ELF32 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: REL (Relocatable file) Machine: Intel 80386 Version: 0x1 Entry point address: 0x0 Start of program headers: 0 (bytes into file) Start of section headers: 64 (bytes into file) Flags: 0x0 Size of this header: 52 (bytes) Size of program headers: 0 (bytes) Number of program headers: 0 Size of section headers: 40 (bytes) Number of section headers: 6 Section header string table index: 3 Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al [ 0] NULL 00000000 000000 000000 00 0 0 0 [ 1] .text PROGBITS 00000000 000130 00001d 00 AX 0 0 16 [ 2] .comment PROGBITS 00000000 000150 00001f 00 0 0 1 [ 3] .shstrtab STRTAB 00000000 000170 00002a 00 0 0 1 [ 4] .symtab SYMTAB 00000000 0001a0 000040 10 5 4 4 [ 5] .strtab STRTAB 00000000 0001e0 000015 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings) I (info), L (link order), G (group), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific) There are no section groups in this file. There are no program headers in this file. There are no relocations in this file. There are no unwind sections in this file. Symbol table '.symtab' contains 4 entries: Num: Value Size Type Bind Vis Ndx Name 0: 00000000 0 NOTYPE LOCAL DEFAULT UND 1: 00000000 0 FILE LOCAL DEFAULT ABS file_data.asm 2: 00000000 0 SECTION LOCAL DEFAULT 1 3: 00000000 0 NOTYPE LOCAL DEFAULT 1 start No version information found in this file. |
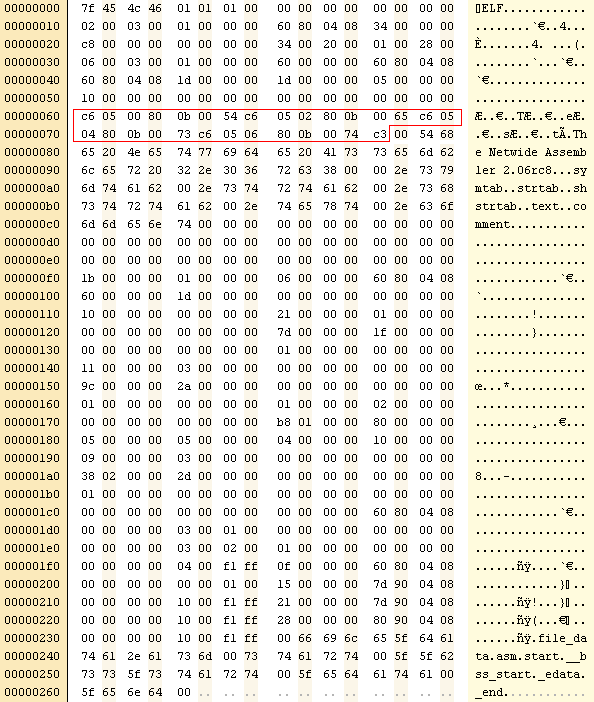
| G:\OSDev\Test\50
cp>i586-elf-readelf -a program.elf ELF Header: Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 Class: ELF32 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: Intel 80386 Version: 0x1 Entry point address: 0x8048060 Start of program headers: 52 (bytes into file) Start of section headers: 200 (bytes into file) Flags: 0x0 Size of this header: 52 (bytes) Size of program headers: 32 (bytes) Number of program headers: 1 Size of section headers: 40 (bytes) Number of section headers: 6 Section header string table index: 3 Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al [ 0] NULL 00000000 000000 000000 00 0 0 0 [ 1] .text PROGBITS 08048060 000060 00001d 00 AX 0 0 16 [ 2] .comment PROGBITS 00000000 00007d 00001f 00 0 0 1 [ 3] .shstrtab STRTAB 00000000 00009c 00002a 00 0 0 1 [ 4] .symtab SYMTAB 00000000 0001b8 000080 10 5 5 4 [ 5] .strtab STRTAB 00000000 000238 00002d 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings) I (info), L (link order), G (group), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific) There are no section groups in this file. Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align LOAD 0x000060 0x08048060 0x08048060 0x0001d 0x0001d R E 0x10 Section to Segment mapping: Segment Sections... 00 .text There is no dynamic section in this file. There are no relocations in this file. There are no unwind sections in this file. Symbol table '.symtab' contains 8 entries: Num: Value Size Type Bind Vis Ndx Name 0: 00000000 0 NOTYPE LOCAL DEFAULT UND 1: 08048060 0 SECTION LOCAL DEFAULT 1 2: 00000000 0 SECTION LOCAL DEFAULT 2 3: 00000000 0 FILE LOCAL DEFAULT ABS file_data.asm 4: 08048060 0 NOTYPE LOCAL DEFAULT 1 start 5: 0804907d 0 NOTYPE GLOBAL DEFAULT ABS __bss_start 6: 0804907d 0 NOTYPE GLOBAL DEFAULT ABS _edata 7: 08049080 0 NOTYPE GLOBAL DEFAULT ABS _end No version information found in this file. |
t y p e d e f s t
r u c t |

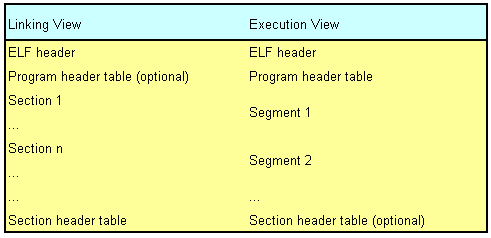
| PT_LOAD:
The array element specifies a loadable
segment,
described by p_filesz and p_memsz. The bytes from the file are
mapped
to the beginning of the memory segment. If the segment’s memory size (p_memsz) is larger than the file size (p_filesz), the ‘‘extra’’ bytes are defined to hold the value 0 and to follow the segment’s initialized area. The file size may not be larger than the memory size. Loadable segment entries in the program header table appear in ascending order, sorted on the p_vaddr member. |
| //in paging.h #define SV 1 // supervisor #define US 0 // user #define RW 1 // read-write #define RO 0 // read-only //in paging.c alloc_frame( get_page(i, 1, kernel_directory), SV, RO); // supervisor and read-only |
| for(
i=KHEAP_START; i<KHEAP_START+KHEAP_INITIAL_SIZE; i+=0x1000 ) alloc_frame( get_page(i, 1, kernel_directory), SV, RW); // supervisor and read/write kheap = create_heap(KHEAP_START, KHEAP_START+KHEAP_INITIAL_SIZE, KHEAP_MAX, 1, 0); // supervisor and read/write |
|
//Allocate user space ULONG user_space_start = 0x400000; ULONG user_space_end = 0x500000; i=user_space_start; while( i < user_space_end ) { alloc_frame( get_page(i, 1, kernel_directory), US, RO); // user and read-only i += PAGESIZE; } |
| ENTRY(_start) OUTPUT_FORMAT(elf32-i386) SECTIONS { . = 0x400100; .text : { *(.text*) } .data : { *(.data*) *(.rodata*) } .bss : { *(.bss*) } } |
| ASFLAGSBIN= -O32
-f bin ASFLAGSOBJ= -O32 -f elf NASM = nasmw CFLAGS= -O -ffreestanding -fleading-underscore CC= i586-elf-gcc LDFLAGS= -T user.ld -Map kernel.map -nostdinc LD= i586-elf-ld all: program.bin program.elf program.bin: program.asm $(NASM) $(ASFLAGSBIN) $< -o $@ program.o: program.asm $(NASM) $(ASFLAGSOBJ) $< -o $@ program.elf: program.o $(LD) $(LDFLAGS) $+ -o $@ # $< Erste Abhängigkeit # $+ Liste aller Abhängigkeiten # $@ Name des Targets |
| all: make_initrd test1.txt file1 test2.txt file2 test3.txt file3 program.elf Test-Programm |
| //process.asm global _file_data_start global _file_data_end _file_data_start: incbin "initrd.img" _file_data_end: //ckernel.c k_memcpy((void*)ramdisk_start, &file_data_start, (ULONG)&file_data_end - (ULONG)&file_data_start); //... if( k_strcmp(node->name,"Test-Programm")==0 ) { address_TEST[j] = buf[j]; } //... k_memcpy((void*)address_user, address_TEST, 4096); // Test-Programm ==> user space |
|
ULONG j; for(j=0x400060; j<0x400100; ++j) { printformat("%d ",*((UCHAR*)j)); } |
| ;program.asm: [BITS 32] start: mov [0x000b8000], byte 'T' mov [0x000b8002], byte 'e' mov [0x000b8004], byte 's' mov [0x000b8006], byte 't' mov [0x000b8008], byte ' ' mov eax, 4 int 0x7F jmp start |
|
i=0; while( i < placement_address + 0x2000 ) //important to add more! { if( ((i>=0xb8000) && (i<=0xbf000)) || ((i>=0xd000) && (i<0xe000)) ) { alloc_frame( get_page(i, 1, kernel_directory), US, RW); // user and read-write } else { alloc_frame( get_page(i, 1, kernel_directory), SV, RO); // supervisor and read-only } i += PAGESIZE; } |
| static void*
syscalls[NUM_SYSCALLS] = { &puts, &putch, &settextcolor, &getpid, &nop, // <------- Nummer 4 &switch_context }; |
| <bochs:1>
lb 0x00400060 <bochs:2> c 400060 (unk. ctxt): mov byte ptr ds:0xb8000, 0x54 <bochs:3> s 400067 (unk. ctxt): mov byte ptr ds:0xb8002, 0x65 40006e (unk. ctxt): mov byte ptr ds:0xb8004, 0x73 400075 (unk. ctxt): mov byte ptr ds:0xb8006, 0x74 40007c (unk. ctxt): mov byte ptr ds:0xb8008, 0x20 400083 (unk. ctxt): mov eax, 0x00000004 400088 (unk. ctxt): int 0x7f .... .... be04 (unk. ctxt): call eax c644 (unk. ctxt): push ebp c645 (unk. ctxt): mov ebp, esp c647 (unk. ctxt): nop c648 (unk. ctxt): pop ebp c649 (unk. ctxt): ret |
| ;program.asm: [BITS 32] start: mov ebx, 0x4 ; 1. Argument mov ecx, 0x0 ; 2. Argument mov eax, 2 ; settextcolor int 0x7F mov ebx, 0x54 ; 'T' mov eax, 1 ; putch int 0x7F jmp start |
| // syscall.c: void syscall_handler(struct regs* r) { if( r->eax >= NUM_SYSCALLS ) return; void* addr = syscalls[r->eax]; int ret; asm volatile (" \ push %1; \ push %2; \ push %3; \ push %4; \ push %5; \ call *%6; \ add $20, %%esp; \ " : "=a" (ret) : "r" (r->edi), "r" (r->esi), "r" (r->edx), "r" (r->ecx), "r" (r->ebx), "r" (addr)); r->eax = ret; } |

| [BITS 32] start: mov ebx, 0x4 ; 1. Argument mov ecx, 0x0 ; 2. Argument mov eax, 2 ; settextcolor int 0x7F mov ebx, 0x54 ; 'T' mov eax, 1 ; putch int 0x7F mov eax, 5 ; switch_context int 0x7F jmp start |


